We all want our FPGAs to perform reliably within their operating environment; indeed, for some designs where the end application is safety- or mission-critical, this is essential. For these applications we need to consider not only the overall architecture of the system, but also how we design our FPGA. There are a number of techniques we can use to ensure the designs we implement within our FPGAs are capable of operating reliably; furthermore, these techniques can be used across a wide range of applications to give better results.
Start from the system level
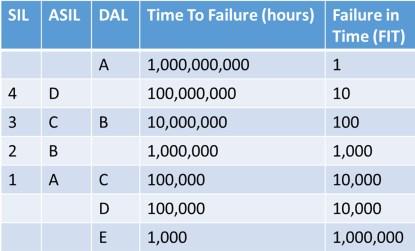
There are a number of different safety standards that are commonly used. Standards such as IEC61508, DO 254, and ISO26262 are oft quoted, but not every engineer understands what they actually mean. In fact, these standards assign numbers defining the time to failure in hours. As would be expected, the higher safety levels require a very high time to failure.
 (Source: Adam Taylor)
(Source: Adam Taylor)
As we see from the above table, it is very difficult to achieve the higher levels without a correctly architected system. Such a system will also likely have to consider dangerous failure modes and single points of failure, which will also need to be eliminated.
All of this can only be achieved by considering the system as a whole and correctly architecting it across the mechanical, electronic, software, and FPGA domains from day one.
Along with the architecture, it is also necessary to develop an engineering management plan that defines the stages of development, the design review gates, the inputs and expected outputs from these gates, and the strategy for verification. Typically, projects working in the safety domain generate a number of documents at all levels of the project; the engineering management plan will identify all of the documents that need to be created. (There is a saying in aviation that when the weight of the documentation equals the weight of the aircraft, that's when it's ready to fly.)
Index
- Start from the system level
- Component selection
- Start at the beginning
- Error detecting and correcting codes
- Communication protocols
- Use of an Arm and Fire mechanism
- Counters
- Safe state machines
- Triple modular redundancy (TMR)
- Verification